Eps 1: attention mechanism in transformer model like bert and gpt
— attention mechanism in transformer model like bert and gpt
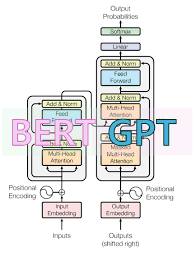
The attention mechanism in transformer models like BERT and GPT allows these models to focus on different parts of the input sequence for understanding context and generating outputs. In BERT, attention is used in a bidirectional manner, considering the context from both left and right for each word, which enhances tasks like question answering and sentiment analysis. GPT, on the other hand, uses unidirectional attention, where the model attends to all previous tokens to predict the next one, making it effective for tasks like text generation and completion. Both models use multiple layers of attention to build a comprehensive understanding of language, significantly improving performance over previous architectures like RNNs and LSTMs.
| Seed data: | Link 1 |
|---|---|
| Host image: | StyleGAN neural net |
| Content creation: | GPT-3.5, |
Host

Sonia Duncan
Podcast Content
In BERT, which is designed for understanding the intricacies of human language, the attention mechanism helps the model comprehend the nuances of word relationships within a sentence bi-directionally. This means that BERT can consider both left and right context simultaneously, leading to a more nuanced understanding. The model computes attention scores that help it focus on relevant words while diminishing the influence of less important ones. For example, when trying to understand the role of "bank" in "He went to the bank to deposit money," attention would help BERT differentiate it from a riverbank context by considering cues from surrounding words.
GPT, on the other hand, focuses primarily on text generation tasks and employs a unidirectional approach, meaning it predicts the next word in a sentence based solely on preceding words. Here, the attention mechanism ensures that the model attends to critical segments of the text generated thus far, allowing it to produce coherent and contextually relevant continuations. When generating text, GPT computes attention scores for each position in the input sequence to capture the dependencies of previous words, making it proficient in storytelling, dialogue generation, and more.
Both BERT and GPT leverage multi-head attention mechanisms to capture different relationships between words using multiple attention layers. This adds a layer of robustness, allowing the model to attend to different aspects of the data simultaneously. For example, one head might focus on syntactic features while another focuses on semantic features, collectively leading to a richer representation.
In summary, attention mechanisms in models like BERT and GPT are game-changers, allowing these transformers to draw meaningful insights from vast amounts of text data efficiently. They help these models capture intricate details and relationships, making them indispensable for tasks ranging from text classification to sophisticated text generation.